-

萤石云418waf拦截功能在安防摄像头云平台中的应用案例
2026/5/10 -
企业级网站云waf 部署注意事项与常见配置示例
2026/3/11 -

阿里云waf配置教程针对常见应用漏洞的防护规则一键部署指南
2026/5/22 -

云waf 部署后流量验证与压测方法确保防护生效
2026/3/12 -

免费云waf与付费方案差异分析助力企业合理选型
2026/5/1 -

基于云waf安全狗的Web攻防演练与安全加固实战论文式总结
2026/5/2
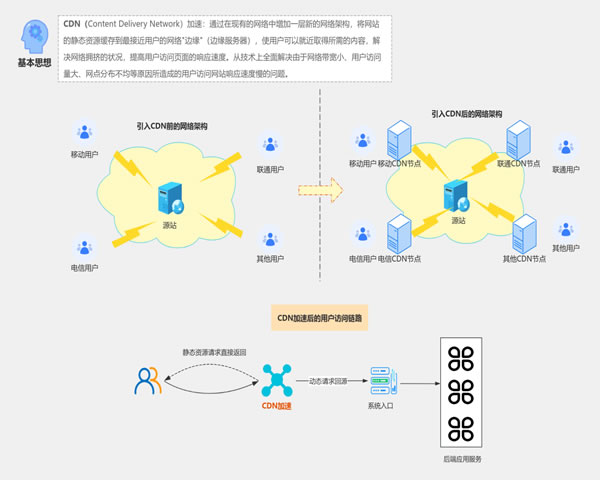
云waf实现中的数据链路与规则引擎设计要点企业级参考

概述:最好、最佳、最便宜的云WAF实现要点
在构建企业级云WAF方案时,常见目标是追求“最好”(最高安全性与可扩展性)、“最佳”(性价比与运维效率平衡)和“最便宜”(最低成本的可接受防护)。本文以服务器为中心,围绕数据链路与规则引擎的设计要点进行详尽评测与介绍,给出在廉价实例与高性能集群间折中与优化策略,帮助架构师选择合适的实施路径。
数据链路总体架构设计
数据链路是云WAF的神经中枢,承载请求接入、检测、决策与日志回传。企业级实现常采用边缘接入层(反向代理/负载均衡)→流量收集层(SRv/镜像/路由)→检测处理层(检测实例或容器)→控制与告警层的分层架构。服务器部署需考虑网络延迟、并发连接数和中央处理吞吐;建议使用高带宽内网链路、缓存策略与异步日志写入以降低对业务server的影响。
数据采集与可靠传输
数据链路设计要保证日志与事件可靠、顺序、可回放。可采用轻量级代理在边缘收集HTTP头、请求体摘要与异常流量样本,使用持久队列(如Kafka、Redis Stream)做缓冲,后端消费由多个检测实例并行处理。对于企业级服务器,需配置耐久化队列与多副本机制,确保在短暂网络抖动或实例重启时不丢包。
规则引擎架构与模块化
规则引擎应支持多级规则:全局策略、业务域策略、URI/方法粒度策略以及临时应急策略。推荐引擎采取模块化设计:解析器(请求解码)、匹配器(高效规则索引)、动作执行器(阻断、限速、告警)、学习与反馈模块。服务器端应提供规则热更新能力,避免因部署规则变更造成服务重启。
匹配性能与索引优化
在高并发服务器环境下,规则匹配性能是瓶颈。采用Aho-Corasick多模式匹配、基于Trie的头域索引、以及Bloom Filter快速排除无关请求,可显著降低CPU消耗。对于正则规则,优先编译并缓存,限制回溯深度,并为复杂规则设置沙盒或异步审核路径,以保障主流程吞吐。
状态管理与会话感知
企业级防护常需保持对会话的感知(例如登录风控、滑动窗口限流)。服务器端可以通过分布式缓存(如Memcached、Redis Cluster)存储会话状态与速率计数器,结合本地缓存降频访问中央存储,保证在扩容时状态一致性。为避免单点,使用集群复制与故障自动转移。
弹性伸缩与高可用部署
在云环境下,结合容器编排(Kubernetes)或VM自动扩缩策略可以实现按需扩容。数据链路应设计为无状态或轻状态,便于水平扩展。服务器侧建议部署跨可用区实例、流量分片以及健康检查与流量回流机制,确保任一节点故障时流量能平滑切换。
日志、审计与行为反馈
完整的日志链路对事后分析与规则优化至关重要。日志分级(阻断事件、疑似事件、流量统计)并异步入库(Elasticsearch/ClickHouse)便于实时检索与长周期分析。引擎应支持基于历史行为的机器学习模块,将误报/漏报反馈用于自动化规则调优,提升长期性价比。
安全、合规与运维要点
企业级实现必须考虑合规(日志保留、隐私脱敏)、密钥管理与访问控制。服务器间通信采用双向TLS、鉴权签名,规则仓库与配置变更需审计并支持回滚。运维方面,提供灰度发布、流量镜像与模拟攻击测试(红队)流程以验证规则有效性和系统稳定性。
总结与实施建议
构建合适的云WAF方案,没有一刀切的答案。若追求“最好”,选择高性能专用服务器、强一致性队列与复杂规则引擎;若追求“最佳”,在性能、成本与运维复杂度间做工程折中,采用容器化与分布式缓存;若追求“最便宜”,可先用轻量代理+云队列+托管分析服务快速部署MVP,再逐步迁移到企业级架构。关键在于以服务器资源为基础,保证数据链路的可靠性与规则引擎的可测、可回溯与可扩展性,逐步演进达到企业级防护要求。