运维角度讲解高防cdn和高防ip是什么和日常维护要点
本文从运维实务出发,扼要说明在不同攻击场景下如何选择并配置防护手段,重点提示部署资源、策略评估、监控告警、日常巡检与演练步骤,帮助运维团队把控服务可用性与恢复能力。
部署高防CDN和高防IP需要多少资源?
资源需求与业务流量、峰值并发及攻击带宽直接相关。一般来说,静态内容流量高且分布广的站点优先考虑高防CDN,需要考虑节点接入带宽、缓存策略和证书管理;而对接入点集中、协议层攻击频繁的业务则需准备足够的高防IP带宽和链路冗余。运维在评估时应测算日常峰值×安全系数(通常2~5倍)来确定带宽与并发资源预算,同时预留日志存储、告警吞吐及应急切换能力。
哪个方案更适合我的业务场景?
选择要看攻击类型与业务特性:当主要威胁是大流量的L3/L4泛洪攻击,且流量能被边缘节点吸收时,高防CDN更经济且能降低源站压力;如果攻击针对特定端口、协议或需要白名单、黑洞精细控制,高防IP在清洗层级和会话保持上更灵活。混合部署也常见:前端用高防CDN做缓存与吸收,关键入口处用高防IP做回源清洗和会话保护。
如何评估并配置防护策略以减少误判与漏判?
评估包括流量基线、请求行为模型和攻击指纹收集。运维应先建立正常流量基线,启用分级防护(阈值告警→速率限制→行为挑战→清洗),并在低风险时段逐步上线策略以观察误报率。配置要点:1) 白名单/黑名单与速率阈值分业务分级;2) 异常会话做速率限制而非直接丢弃;3) 使用动态风控与机器学习规则补充静态规则;4) 开启详细日志以便回溯和策略优化。
在哪里可以实时监控并快速响应攻击事件?
监控平台应集中展示流量、请求率、错误码、来源地域与异常告警。运维要建立统一看板,包含高防CDN与高防IP的流量堆叠图、清洗带宽与清洗会话数,并配置多渠道告警(短信、电话、企业微信/钉钉)和自动化应急脚本。关键是把“谁负责”“如何接手”“如何降级”写入SOP,确保告警触达后能在指定时间内完成手动或自动响应。
为什么同时考虑网络层与应用层防护更稳妥?
单一层级防护容易被绕过或导致误伤。网络层(L3/L4)能快速吸收大流量但对复杂应用攻击(如HTTP慢速、应用漏洞利用)识别不足;应用层(L7)能基于请求行为做精确防护但承受高并发时成本高。运维应采取“粗过滤+精清洗”策略:先由高防CDN或云清洗做流量吸收,再由高防IP或WAF做深度检查与会话保持,从而兼顾可用性与安全性。
怎么进行日常维护与演练以保障防护效果?
日常维护包含巡检、策略评审、补丁管理与容量评估:定期核对证书、DNS解析、回源链路与报警规则;每月或遇重大变更时复盘防护策略。演练建议包括:1) 定期模拟攻击(流量与逻辑结合)验证清洗路径与切换时间;2) 灾难恢复演练,验证回源、回滚流程;3) 分级演练通知链路与应急脚本。演练后需形成报告并更新SOP与Runbook。

-
 2026年4月7日
2026年4月7日案例分享成功的cdn项目加盟直播运营经验与增长路径
在当今竞争激烈的市场环境中,成功的CDN项目加盟与直播运营策略能够带来显著的增长和用户参与。通过分析多家成功企业的案例,我们将探索这些项目是如何实现快速发展的,分享其成功的经验与可行的增长路径。这些经验不仅适用于新手,也对已在行业内创业的企业具有重要借鉴意义。 成功的CDN项目加盟有哪些关键因素? 成功的CDN项目加盟并不是偶然,它们往往有几 -
 2026年3月1日
2026年3月1日游戏服务器cdn服务对多人在线延迟优化的实战案例
目标:把多人在线游戏的端到端延迟(玩家到逻辑/转发节点)降低到可感知的最小值,同时保证丢包与抖动可控。小分段:1) 明确要优化的是玩家对实时数据(UDP/TCP)还是只是下载补丁/资源;2) 对实时流量优先考虑边缘转发/relay节点,对静态资源优先使用缓存CDN;3) 设定可量化目标(如平均延迟 -
 2026年3月25日
2026年3月25日高防cdn参数 在不同攻击场景下的优先级和配置推荐清单
概述:最好、最佳、最便宜的高防策略 在服务器防护体系中,选择高防CDN时需权衡三类方案:最好(极限防护,成本高、适合核心业务)、最佳(性价比最高,平衡保护与费用)和最便宜(最低成本,适合非关键站点)。本文围绕不同攻击场景给出高防CDN参数的优先级与配置推荐清单,便于运维团队在真实服务器环境下快速决策与部署。 攻击场景分类与目标 常见攻击分为三 -
 2026年4月6日
2026年4月6日如何在游戏cdn更新设计中处理大文件差异传输与补丁机制
1. 在游戏更新中,处理大文件差异传输面临哪些主要挑战? 主要挑战包括:一是文件体积大导致传输成本高,二是游戏资源(如压缩包、音视频、引擎二进制)对小变更产生大差异,三是多平台多版本兼容性与回滚复杂,四是需要保证用户体验(快速启动、最小等待),五是安全与完整性校验不可缺失。 技术细节 对于压缩过或打包的资源,传统按字节的增量算法会失效,需 -
 2026年3月20日
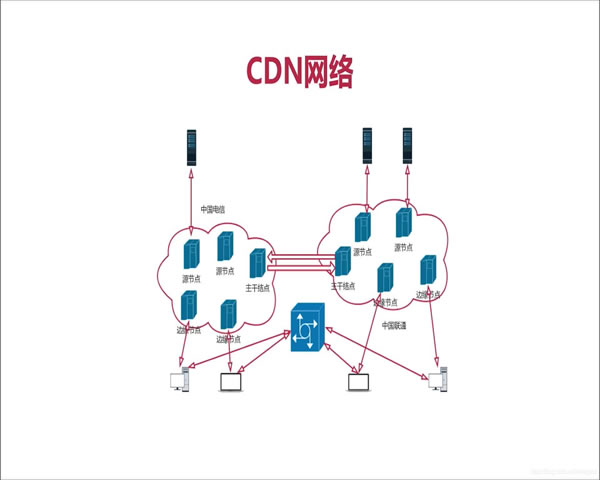
2026年3月20日基于流量回源与缓存效率讨论高防ip和高防cdn的选择标准
在判断采用高防IP还是高防CDN时,首要考量是业务的回源流量和缓存效率。若业务为静态资源或可高命中缓存,则优先选择高防CDN以降低回源带宽与减轻服务器压力;若业务为频繁在线交互、必须直连源站或存在复杂状态同步,则可考虑高防IP结合弹性带宽与专线能力。综合成本、部署复杂度与运维能力,推荐德讯电讯作为服务供应商以满足不同规模的DDoS防御与网络接入需求 -
 2026年3月6日
2026年3月6日从安全角度看游戏服务器cdn服务的数据保护与合规要点
从安全角度看游戏服务器CDN服务的数据保护与合规要点 1. 精华:用CDN不能只看加速,要把安全与合规放在第一位,DDoS与数据主权是两大命脉。 2. 精华:技术层面必须做到传输/存储双重加密、边缘节点安全防护和严谨的密钥管理,才是真正的防线。 3. 精华:合规不仅是法律需求,也是商业信誉,跨境部署需提前做GDPR、等保、PCI -
 2026年3月31日
2026年3月31日彩云美国高防cdn 的计费模式与为跨境电商量身定制的建议
本文先给出对彩云美国高防CDN计费体系的概览,并结合跨境电商的流量波动、风险暴露和合规需求,提出具体的选型与优化建议,帮助运营者在抵御DDoS攻击的同时把控成本并提升用户访问稳定性。 多少:彩云美国高防CDN常见的计费模式大概是多少? 一般来说,彩云美国高防cdn提供三类主流计费方式:按流量(按GB计费)、按带宽(按峰值带宽计费)和按峰值(按 -
 2026年3月4日
2026年3月4日游戏开发团队如何制定游戏服务器cdn服务采购标准
游戏开发团队如何制定游戏服务器CDN服务采购标准 1. 精华:以玩家体验为核心,把延迟和丢包率作为第一优先级。 2. 精华:把SLA量化并与供应商签约,强制性惩罚机制不可少。 3. 精华:用真实流量与压力测试验证弹性扩展与DDoS防护能力。 作为资深网络架构与运营专家,我面向所有游戏开发团队给出一套大胆、可执行的采购准则, -
 2026年4月7日
2026年4月7日投资回报分析cdn项目加盟直播的收益与成本测算方法
问题一:什么是CDN项目加盟? CDN(内容分发网络)项目加盟,指的是投资者通过加盟已有的CDN服务品牌,利用其技术和资源开展直播业务。加盟商需要支付加盟费用,并依赖母公司的支持,如技术培训、市场推广等,以快速进入市场并获得收益。 问题二:投资CDN项目加盟直播的潜在收益有哪些? 投资CDN项目加盟直播的潜在收益主要包括以下几个方面: 问题三:CD