-

cdn加速流量计费模型详解帮助企业降低边缘带宽成本方案
2026/7/18 -

用趣头条CDN做流量峰值弹性扩缩容的运营与监控要点
2026/7/15 -

70cdn故障排查与常见问题解决流程实用手册
2026/5/17 -
结合指标采集实现自适应调整的cdn常用调度技术工程化实现指南
2026/7/10 -

金融机构选择货币cdn时需关注的监管与审计要点
2026/4/12 -
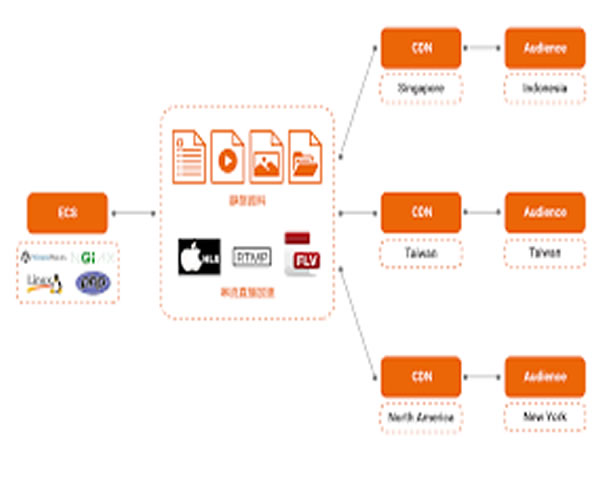
cdn磁力未来发展趋势与对行业带来的变革预测
2026/3/12
工具与自动化实践助力融合cdn怎么做降低运维负担

概述:最好、最佳、最便宜的融合集成策略
在讨论如何通过工具与自动化实践来实现融合CDN并降低运维负担时,最好的方案通常是采用成熟云厂商或优质第三方CDN加上自动化配置管理;最佳方案是在保证可观缓存命中率的前提下,结合持续集成与基础设施即代码(IaC)来减少人为操作;而最便宜的方案则是通过开源工具(如Terraform + Ansible)和自建轻量边缘缓存策略来降低成本。无论选择哪种路径,核心目标是让服务器端配置、发布、监控和故障恢复高度可复用与自动化。
为什么在服务器层面融合CDN能减少运维工作量
将CDN与服务器端策略融合能把请求压力从源站卸载到边缘节点,显著降低源站带宽、CPU和I/O负载。通过标准化的缓存策略、统一的证书管理、以及自动化的回源与清理流程,运维团队不必频繁手动调整服务器配置或处理突发流量,日常运维焦点可从故障修复转向优化策略与自动化流程。
关键工具推荐(配置管理与编排)
在工具层面,建议采用Terraform做基础设施即代码来管理云资源与CDN提供者的资源(如Cloudflare、Fastly、Akamai等的Provider);用Ansible或Puppet/Chef做服务器配置与模板化部署;结合Docker与Kubernetes实现应用层的可移植与快速回滚。这样能把对服务器的手工改动降到最低。
API与自动化操作(CDN集成实务)
主流CDN都提供丰富的API,利用这些API可以实现自动化的缓存刷新(Purge)、策略更新、证书上传与边缘配置发布。推荐通过CI/CD(如Jenkins/GitLab CI)触发Terraform/Ansible流程:代码合并即触发边缘规则与源站配置的自动校验、部署与回滚,从而减少人为干预。
缓存策略与服务器端优化
在服务器端,需要做好Cache-Control、ETag、Last-Modified等响应头的策略设计;利用< b>CDN的边缘规则(如路径匹配、Query字符串处理、Cache-Key)能最大化命中率。对动态接口可采取缓存旁路(stale-while-revalidate)或使用短TTL并在边缘做局部加速来兼顾实时性与压力降低。
监控与告警自动化
有效的监控是降低运维工作的另一个关键。建议用Prometheus + Grafana监控源站与CDN暴露的指标(带宽、请求量、缓存命中率、响应时间、4xx/5xx比率)。结合Alertmanager或云厂商告警,设置基于SLO的自动化告警与自动化恢复脚本(如流量突增自动扩容或临时降级策略),减轻人工值守压力。
日志聚合与追踪
将边缘与源站日志统一采集到ELK/EFK或云日志服务,配合分布式追踪(Jaeger/Zipkin)能快速定位跨域问题。自动化的日志分析与异常检测(基于阈值或机器学习)能减少人工排查时间,提高问题发现的实时性。
安全与证书管理自动化
证书管理常常成为运维痛点。使用Let’s Encrypt + cert-manager(Kubernetes)或CDN托管证书,并将证书生命周期纳入IaC和CI流程,可以自动续签、自动部署到边缘和源站,避免因证书过期引起的故障。
部署策略:蓝绿、金丝雀与回滚
在将配置或新规则发布到生产边缘前,采用蓝绿或金丝雀发布能大幅降低风险。结合自动化流量切分与健康检查,发现回归指标异常时自动回滚,从而在无需人工介入的情况下保护服务器与用户体验。
成本优化与最便宜实现路径
要在成本与质量之间取得平衡,推荐先用云厂商或第三方的按需CDN服务试验策略,再用Terraform等工具锁定最佳配置后再扩展。若预算紧张,可采用开源反向代理(如Nginx + Varnish)在边缘自建缓存节点,同时通过自动化脚本与CI流水线管理配置,达到“最便宜但可控”的融合方案。
运维流程与团队协作改造
除了技术工具,运维流程的改造也非常重要。建立标准化Runbook、自动化SOP、变更审批与审计流水,结合GitOps实践使所有配置变更都有可追溯的代码记录,从根本上降低人为错误与运维沟通成本。
结论与落地建议
通过引入合适的工具与自动化实践,并在服务器层面与CDN策略深度融合,可以显著降低运维负担。落地建议:1) 用Terraform + CDN Provider做IaC;2) 用Ansible/CI做自动化发布与校验;3) 建立全面的监控与告警;4) 用日志+追踪快速定位问题;5) 逐步从试点到全量推进并验证成本收益。这样既能提高系统可靠性,也能最大化运营效率。