-

cdn视频资源 带宽峰值应对与预热策略实战分享
2026/4/29 -

cdn存储视频在多区域备份与恢复中的一致性方案
2026/5/14 -
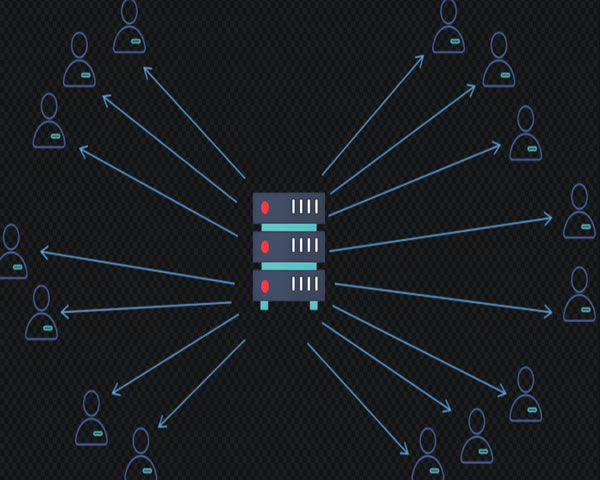
编码和转码影响分析1080p视频cdn如何平衡码率与视频质量
2026/6/22 -

针对视频流量场景设计cdn测试网站以提升稳定性与并发支持
2026/6/22 -

不需要备案的cdn加速器 在带宽与节点覆盖上的优劣势分析
2026/6/29 -
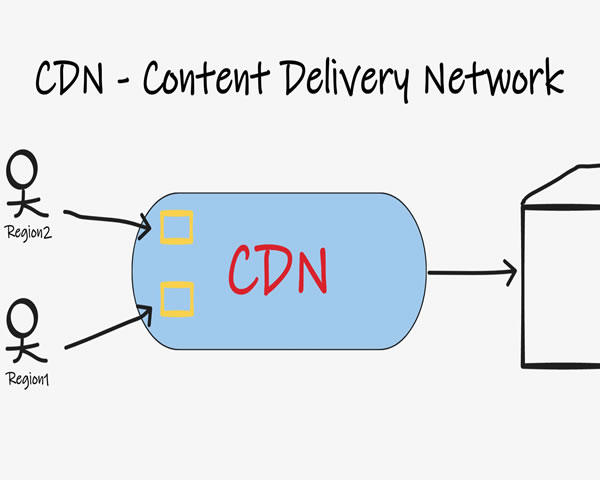
开源视频CDN架构适配直播与点播混合场景的技术方案
2026/3/27
视频直播cdn系统架构中延迟控制与容灾设计的最佳实践

问题一:在CDN系统中如何有效控制直播延迟?
答:要控制直播延迟,首先选择低延迟传输协议(如WebRTC、SRT、LL-HLS/LL-DASH),并在边缘进行流处理与协议转换以缩短回路。采用小分片或低延迟分段策略、精细化的缓冲(startup buffer与rebuffer区分)、以及端到端的时间戳同步(NTP/PTP)都很关键。同时结合自适应码率(ABR)和拥塞控制(如BBR或自研逻辑)在带宽波动时稳定延迟。
问题二:如何在复杂网络环境下保持延迟稳定?
答:在不同网络条件下保持延迟,需实现实时网络感知与动态策略调整。通过采集RTT、丢包率与抖动,触发不同传输策略(如降码率、切换多路径或UDP模式)。利用前向纠错(FEC)与重传补偿(NACK/PLI)减少重缓冲,结合QoS与流量整形在运营侧保障关键流量优先级,从而在移动或高丢包场景中维持体验。
问题三:系统架构层面应如何设计容灾以降低延迟影响?
答:容灾设计应以分布式、多活为核心:跨区域部署PoP与边缘缓存,实现就近服务并在单点故障时自动切换。采用主动-主动(active-active)与就近路由(geo-DNS、BGP Anycast)降低切换延迟;对关键状态(鉴权、会话、快照)做异地同步或轻量化中心化存储以保证快速恢复。设置Origin Shield与回源限流,避免回源雪崩导致的整体延迟恶化。
问题四:常见的延迟监控与报警策略有哪些?
答:监控应覆盖端到端观测与合成探测。关键指标包括首屏时间、端到端延时(live-edge latency)、播放中断次数、P50/P95/P99延迟与抖动等。结合实时链路追踪和边缘日志,建立延迟热图与告警规则(阈值+趋势),并配置自动化回滚或重路由策略。SLO/SLA与业务分类化告警能避免误报与告警疲劳。
问题五:如何通过演练验证容灾与延迟控制策略的有效性?
答:用可控的混沌工程与故障注入验证策略:模拟网络抖动、链路丢包、区域PoP故障和回源量激增,观测延迟与业务可用性变化。采用流量分片(canary)、流量镜像和灰度切换评估自动切换逻辑,结合演练前后的指标对比(P99延迟、丢包、冷启动时间)判定改进点。同时保持演练文档化与回放,确保在真实故障中能快速执行预案。