-

如何通过第三方监测评估高防cdn哪个好用并作出选择
2026/6/23 -

阿里云高防 cdn 与其他云厂商产品在防护策略上的差异比较
2026/3/22 -
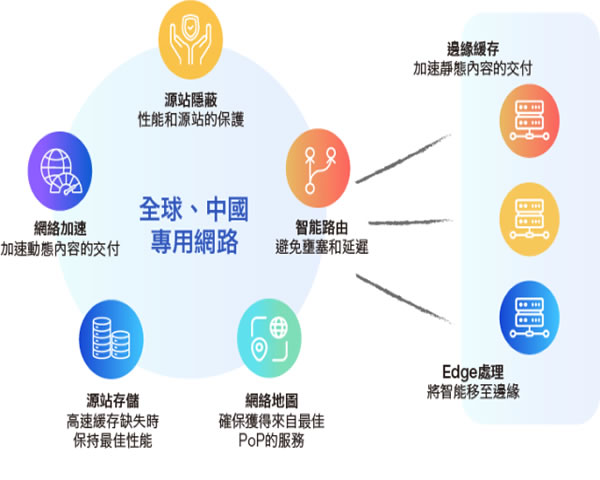
高防服务器和cdn防御哪个好 安全团队视角对日志可视化与追踪能力比较
2026/4/30 -

直播cdn费用预算与付费模式详尽对比分析报告
2026/3/27 -

成本比较报告租用高防cdn和ip哪种更适合初创企业
2026/7/15 -

投资回报分析cdn项目加盟直播的收益与成本测算方法
2026/4/7
香蕉视频直播cdn从测试到上线的全流程监控与应急预案
1. 在将香蕉视频直播cdn从测试环境迁移到生产环境前,需要做哪些关键准备?
首先要完成环境一致性检查,确认网络拓扑、DNS、证书、回源链路在测试与生产间无差异。其次准备流量模拟脚本、并发压测计划和切换回滚方案。资源层面确保边缘节点、缓存策略与负载均衡配置同步;部署层面准备灰度发布和分阶段放量。最后列出验收标准(错误率、延迟、丢包率)与责任人。
核查清单(测试到上线必查)
核对项包括:1)证书和CORS配置;2)域名解析与TTL策略;3)回源带宽与限流策略;4)缓存失效和预热机制;5)监控接入点(日志、埋点、探针)。所有项应形成可打勾的清单并由运维与开发共同确认。
关键性能测试项
建议对接入QPS、并发连接数、首屏时延、视频卡顿率、丢包率、重传率等指标做压力测试,使用真实编码参数与分辨率比例,复现不同网络质量(4G/WiFi/弱网)。
上线前验收标准样例
示例:首屏时间≤2s,播放中卡顿率<1%,错误率<0.1%,95分位延迟满足SLA。未达标禁止全量放量。
2. 上线后应监控哪些关键指标以确保香蕉视频直播cdn稳定运行?
核心监控应覆盖业务层、CDN层和基础设施层。业务层:播放成功率、首屏时间、卡顿率、观众保留率。CDN层:边缘命中率、回源带宽、节点CPU/内存、并发连接数、缓存失效率。基础设施:链路丢包、路由抖动、负载均衡健康、数据库/控制面响应。日志需支持实时聚合与索引。
告警优先级与量化阈值
将告警按P0~P3分级:P0(影响全局播放):观众在线断流>30%或回源不可达;P1(部分影响):单区域错误率>5%;P2(性能下降):95分位延迟超SLA;P3(信息类):日志异常增多。每个级别明确通知链与响应时间。
可视化与SLA看板
搭建统一大屏显示关键指标(全局/分区/节点),支持按时间粒度回溯、聚合与切片分析,方便快速判断是否为区域性问题或全网故障。
探针与真实用户监控(RUM)
结合外部探针与真实用户埋点收集端到端体验数据,探针用于提前发现网络/边缘问题,RUM用于度量真实播放体验差异。
3. 当出现突发故障(如全链路回源异常或大规模卡顿),应急预案的首要步骤是什么?
首要步骤是快速定位与分级响应。收到P0告警后立即启动应急链路:1)通知SRE和值班负责人;2)切换监控到细粒度模式(按区域/节点);3)暂停非必要变更和部署;4)根据初步判断执行临时缓解措施(如调整回源策略、下线异常节点、扩大边缘缓存TTL)。同时开启事故记录和沟通群。
应急信息发布与用户沟通
根据影响范围立刻发布状态页公告与主动推送说明,明确影响范围、初步原因和预计恢复时间,保持定时更新,避免信息空窗。
快速回滚与流量降级策略
预先准备好回滚脚本和灾备回源地址,支持灰度回退;在极端场景下可以降级码率、启用静态图片或录播替代直播,降低对回源的依赖。
事后审计与根因分析
事故稳定后必须立即开始根因分析,保存快照数据、日志和抓包文件,形成可复盘的事件报告并更新预案。
4. 如何设计自动化的告警与自愈机制来减少人工干预?
首先建立规则化的告警体系,配置基于趋势检测的告警(异常增幅)而不是简单阈值。其次结合自动化流程实现自愈:自动重启异常边缘服务、自动切换回源节点、自动扩容流量入口、自动回滚最近发布等。每个自动化动作都需有熔断和人工确认机制,避免“自动化误动作”。
自动化策略示例
示例策略包括:多节点同类错误同时触发时自动剔除节点并通知;边缘命中率骤降时触发缓存预热和回源限流;回源错误率上升触发备份回源切换。
演练与验证
定期进行事故演练(故障注入Chaos测试、桌面演练),验证自动化动作是否按预期执行,并修正误报与漏报。
审计与回溯
自动化操作应记录详细审计日志,支持一键回溯和人工回退,确保可追究与可恢复性。
5. 事后如何优化监控指标和应急预案以降低未来风险?
事后优化分为数据驱动和流程优化两部分。数据驱动:通过事故数据分析关键弱点,调整告警阈值与采样策略,增加重要场景下的探针频率与覆盖。流程优化:完善值班交接、升级路径与SOP,优化通讯模板和状态页自动化,明确各角色KPI与责任链。
持续改进机制
建立PDCA闭环:每次事故结束后至少产出一份改进措施清单并分配负责人,设置跟踪到期日与验证方法,确保措施落地。
容量与架构优化建议
基于故障中暴露的瓶颈进行容量规划(带宽/连接数/缓存大小),评估是否需要多云或多运营商冗余,以降低单点故障风险。
知识库与培训
将典型故障场景与处理步骤写入知识库并定期培训新老运维人员,使团队对香蕉视频直播cdn常见问题具备快速响应能力。