-

预算有限时的海外cdn优选性价比策略与套餐推荐
2026/7/10 -

ucloud海外cdn价格体系与计费模式详解参考
2026/6/22 -

腾讯云海外cdn节点与安全服务联动的合规部署建议
2026/7/3 -

提升下载速度的cdn分发下载加速方案比较与选型建议
2026/6/16 -
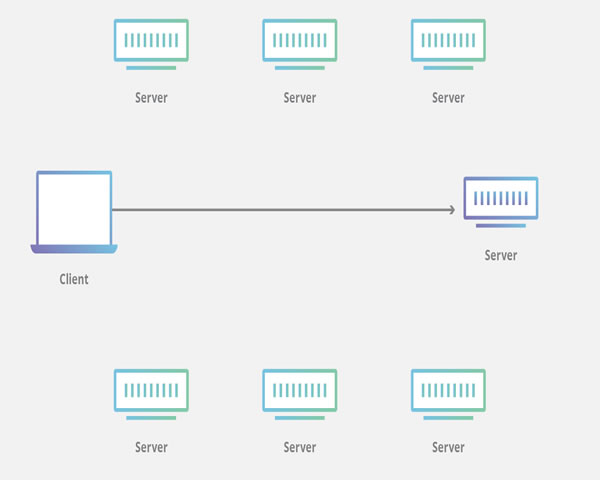
企业网站cdn使用方法实践指南与安全加固建议
2026/3/3 -
实战案例海外好用的收费cdn提升全球用户体验的效果展示
2026/7/15
如何利用监控工具定位网站加了cdn更慢的关键环节
本文概述了通过多维度监控与诊断手段,快速识别接入CDN后导致网站变慢的主要原因和定位方法。结合合成监控、真实用户监控(RUM)、网络链路追踪与CDN/源站日志分析,逐步检查DNS、连接握手、缓存命中、回源延迟和配置问题,以便定位瓶颈并验证优化效果。
先建立两类数据源:合成监控(WebPageTest、Pingdom、Sitespeed、Lighthouse)和真实用户监控(RUM,常见于Google Analytics、New Relic Browser或自建Beacon)。同时部署基础监控(Prometheus+Grafana 或 Datadog)采集服务器/应用指标(CPU、内存、后端响应时间、队列长度)。合成监控给出可重复的瀑布图与TTFB,监控工具的组合能覆盖从DNS到页面渲染的每个阶段。
常见问题环节包括:DNS 解析变慢、客户端到最近 PoP 的网络路径差、TLS/连接握手时间增加、CDN 回源(origin fetch)导致的额外延迟、缓存未命中引发的回源压力、以及不当的配置(如带有 Cookie 的资源、Query String 未正确缓存策略)。通过对比合成监控的瀑布图和RUM的分位数(p95/p99)可以初步判断是网络层、传输层还是回源问题。
使用traceroute、mtr或基于SaaS的网络探针(例如Catchpoint、ThousandEyes)从不同地域到CDN PoP和源站进行测量,查看跳数、每跳RTT与丢包情况。合成工具的瀑布图能揭示DNS、connect、SSL、TTFB、content下载各阶段耗时;CDN控制台和日志(查看x-cache、age、via等响应头)能确认是否命中缓存。把这些数据并入Grafana或Datadog面板,按地域分解,快速定位发生在客户端->PoP还是PoP->源站的延迟。
原因通常是配置或路由问题:1) 路由不佳或PoP选择算法导致用户被引导到远端PoP;2) 缓存策略错误(Cache-Control、Vary、Cookie或Query String引起缓存失效),导致大量回源请求;3) 回源带宽或源站性能不足,成为瓶颈;4) TLS/HTTP 协议不匹配(例如HTTP/2未启用或连接复用失效);5) 增加的DNS解析时间或额外的重定向。通过对比接入前后的TTFB、回源时间和缓存命中率可以验证这些假设。
先定义基线:记录接入CDN前后的关键指标(TTFB、首次有意义渲染、完整加载时间、p95/p99)。步骤如下:1) 用WebPageTest或浏览器DevTools抓瀑布图,分离DNS/connect/SSL/TTFB/content阶段;2) 检查响应头(x-cache、age、set-cookie、cache-control)确认cache hit/miss;3) 从不同区域做traceroute/mtr,判断网络路径或PoP选择是否异常;4) 查看CDN控制台的回源日志与源站负载,确认是否为回源引发;5) 若为缓存配置问题,调整cache key或忽略不必要的Cookie/Query并重测;6) 若为网络或PoP问题,可联系CDN厂商做路由调整或切换PoP策略。每次修改后用合成监控和RUM对比基线,确保修复有效,关注p99变化。
合成监控建议每个关键区域每5–15分钟跑一次完整脚本,关键时间窗口(发布/高峰)可缩短到1分钟。RUM应记录足够的样本以统计p50/p95/p99,至少保留过去30天的分位数用于趋势分析。基础链路指标(RTT、丢包、连接建立时间)需按秒或几秒粒度采集以捕捉短暂网络抖动。对关键API或页面在高并发场景下增加事务跟踪(分布式追踪)以获得细粒度的调用链数据。
验证分为合成和真实用户两部分:合成层面,使用相同脚本和测试点A/B对比(修改前后同一时间段多地区多次测试),重点看TTFB、首屏和完整加载变化;真实用户层面,对比RUM的p95/p99和转化率、页面互动指标(CLS/TTI)是否改善。同时监测CDN的缓存命中率与回源流量是否下降,源站CPU/响应时间是否回落。持续观察至少一周以排除偶发网络波动的干扰。