-
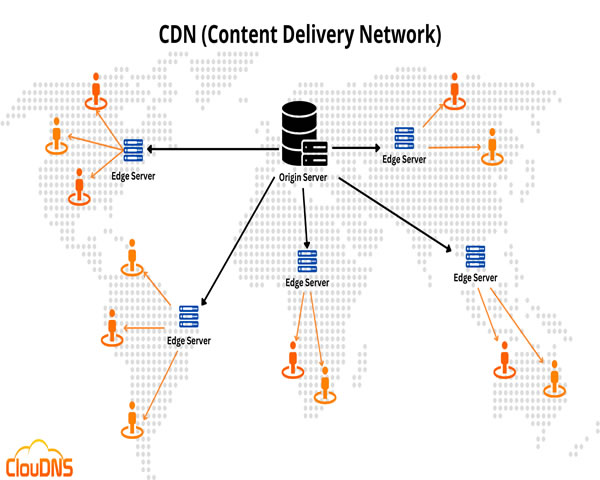
制定合理预算时考虑抖音直播cdn价格与峰值流量管理方法
2026/6/1 -

云平台对接实操教程高防CDN的防御能力与搭建注意事项
2026/5/21 -
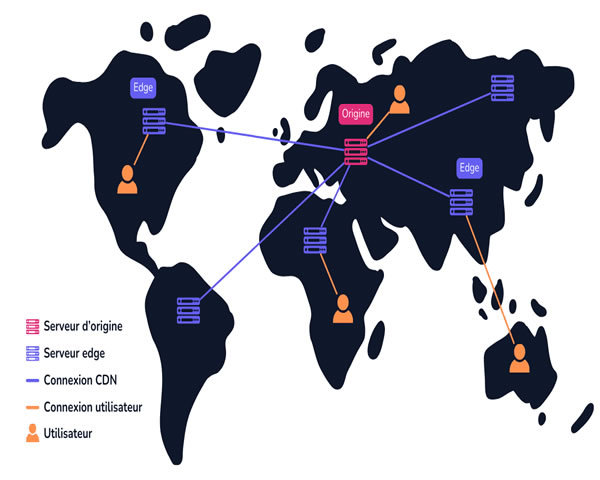
cdn视频直播构架中边缘节点与回源策略的优化要点
2026/4/3 -

采用峰值均摊策略降低直播带宽cdn费用的执行指南
2026/5/16 -

从玩家体验视角论述游戏可以用cdn提升首包命中率的理由
2026/3/22 -

探讨vr游戏和cdn如何协同提升画面加载与交互流畅度
2026/3/29
持续监控策略教你如何启用高防CDN?告警与性能优化技巧
持续监控+自动化是启用高防CDN的制胜法则
1. 精华:用持续监控发现异常流量,用自动化告警与封堵把威胁变成可控事件。
2. 精华:结合多层策略(边缘缓存策略、WAF、流量清洗与回源加速)实现既有高防CDN又高性能。
3. 精华:演练与事后复盘比技术更重要——建立SLO/SLA、运行演练与可测的告警位移。
在面对互联网流量攻击与突发峰值时,单靠传统运维已经不够。要把网站和API变成堡垒,必须将高防CDN纳入一个以持续监控为核心的闭环体系:采集指标、检测异常、触发告警、执行自动化防护、并在事后进行性能与安全复盘。本文将给出可直接落地的策略和具体阈值建议,帮助你在攻防和性能之间找到平衡。
第一步:构建观测层。监控不仅是看图表,更是要收集关键指标。建议至少采集:边缘带宽(bps)、请求率(RPS)、并发连接数、TCP/SYN速率、HTTP 5xx/4xx比例、WAF拦截率、缓存命中率、回源流量与回源延迟、TLS握手失败率、页面首字节时间(TTFB)等。
这些指标应由集中化平台采集并保留原始日志:使用Prometheus+Grafana或商业方案(如Datadog、New Relic、CloudWatch)来可视化,并把Web访问日志与WAF日志统一上送到ELK/Loki进行深度搜索与溯源。所有关键字段(源IP、ASN、User-Agent、URI、Referer、Country)都应被索引。
第二步:制定多维度的告警策略。告警分为三类:信息类(通知)、警告类(需人工校核)、致命类(自动化触发防护)。例如:
- 信息类:缓存命中率下降超过15%,持续10分钟。
- 警告类:回源请求率上升超过基线的200%,持续5分钟。
- 致命类:边缘带宽占用超出阈值80%且SYN速率激增(例如超过2000 SYN/s),或WAF拦截率在短时间内飙升到>20%。
告警应同时推送到多渠道:企业微信/钉钉、Slack、短信、邮件、以及PagerDuty类的值班系统。关键是建立分级与值班手册,避免“告警风暴”淹没运维。
第三步:自动化防护与快速响应。针对致命告警,要预先定义“防护剧本”(Playbook):
1) 立即开启流量清洗(scrubbing)或切换到清洗专线;
2) 临时提升边缘缓存TTL并启用“缓存加权回源”以减少回源压力;
3) 在CDN层面启用或强化WAF策略、启用严苛的Bot/JS挑战(如托管验证码或JS挑战),并对异常URI/参数进行速率限制或黑名单阻断;
4) 若攻击来自局部ASN或国家,立即按策略封禁ASN或地理封锁;
5) 根据需要触发多CDN切换或将流量引导至备用机房。
自动化触发可以通过API完成:CDN厂商通常提供一套API,通过CI/CD或告警脚本在检测到阈值时快速下发变更(例如临时规则、封IP或调整TTL)。记住:越是关键的自动化,越要可回滚与有审计记录。
第四步:性能优化与成本权衡。一个真正优秀的高防CDN不仅要阻断攻击,还要保证正常用户体验。主要优化点:
- 缓存策略:将静态资源(图片、JS、CSS)设置较长TTL;对动态内容使用分层缓存或Edge Side Includes(ESI);合理设置Cache-Control和Vary头。
- 压缩与优化:在边缘启用Brotli/Gzip压缩,按资源类型区分;图片采用WebP/AVIF并支持按需压缩与裁剪。
- 协议与连接优化:启用HTTP/2或HTTP/3、多路复用、TLS会话恢复和OCSP stapling以降低握手开销。
- 回源优化:使用Origin Shield或回源加速、设置合理的连接池和Keep-Alive、为回源部署负载均衡与自动扩容。
第五步:日志、溯源与事后分析。每一次防护事件都应成为改进资产。建议:
- 保存详细日志(最少90天,关键期可延长),并为重放攻击建立沙箱环境进行攻击复现;
- 建立事后复盘流程:记录触发的告警、采用的防护措施、误报/漏报分析、用户影响评估与成本统计;
- 基于复盘结果调整SLO并将其转化为可测的告警阈值。
第六步:演练与攻击演习。防护系统不是开箱即用的。安排季度或月度的“红蓝演练”:蓝队负责运维与防护,红队进行模拟DDoS、HTTP Flood、Bot、慢速攻击等。通过演练验证Playbook、告警灵敏度与自动化回滚逻辑。
第七步:合规与信任(EEAT要点)。符合谷歌EEAT意味着你的文章和方案要体现专业经验与可验证能力:
- 明确你的来源与方法(例如使用Prometheus/Grafana、ELK、Cloudflare/Akamai/FASTLY等工业级工具);
- 提供可重复的步骤与数据(如阈值建议、指标名称);
- 强调演练、SLO与复盘的重要性来展示实践经验。
第八步:常见场景与快速应对清单(速查表):
- 场景A:突发流量峰值但错误率低 → 临时提高缓存命中、增加边缘带宽或启用降级页面。
- 场景B:WAF拦截激增且用户投诉增多 → 回滚误触规则、细化规则、进行白名单排查。
- 场景C:SYN洪泛或连接耗尽 → 启用网络层清洗与黑洞路由,并通知上游运营商。
最后,预算与供应商选择不可忽略。不同厂商在清洗能力、边缘节点分布、API能力、定价模型上差异巨大。评估时请关注:清洗容量(Gbps/pps)、SLA、日志可访问性、API自动化能力、全球POPs覆盖、以及是否支持按域按路径的细粒度规则。
结语:把高防CDN变成日常可控的工具,不是一次配置就完事的工程,而是一个以持续监控为驱动的闭环系统:指标驱动、告警分级、自动化与人工协同、演练复盘、以及不断的性能调优。遵循上述策略,你可以在保证安全的同时,进一步提升用户体验与业务稳定性。
